什么是机器学习
关于什么事机器学习,一直没有一个统一的定论。第一个机器学习的定义来自于Arthur Samuel。他定义机器学习为,在进行特定编程的情况下,给予计算机学习能力的领域。
Samuel的定义可以回溯到50年代,他编写了一个西洋棋程序。这程序神奇之处在于,编程者自己并不是个下棋高手。但因为他太菜了,于是就通过编程,让西洋棋程序自己跟自己下了上万盘棋。通过观察哪种布局(棋盘位置)会赢,哪种布局会输,久而久之,这西洋棋程序明白了什么是好的布局,什么样是坏的布局。然后就牛逼大发了,程序通过学习后,玩西洋棋的水平超过了Samuel。这绝对是令人注目的成果。尽管编写者自己是个菜鸟,但因为计算机有着足够的耐心,去下上万盘的棋,没有人有这耐心去下这么多盘棋。通过这些练习,计算机获得无比丰富的经验,于是渐渐成为了比Samuel更厉害的西洋棋手。上述是个有点不正式的定义,也比较古老。另一个年代近一点的定义,由Tom Mitchell提出,来自卡内基梅隆大学,Tom定义的机器学习是这么啰嗦的,一个好的学习问题定义如下,他说:
1, 一个程序被认为能从经验E中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理 T 时的性能有所提升。
我认为他提出的这个定义就是为了压韵
在西洋棋那例子中,经验e 就是程序上万次的自我练习的经验而任务 t 就是下棋。性能度量值 p呢,就是它在与一些新的对手比赛时,赢得比赛的概率。
在这些视频中,除了我教你的内容以外,我偶尔会问你一个问题,确保你对内容有所理解。说曹操,曹操到,顶部是Tom Mitchell的机器学习的定义,我们假设您的电子邮件程序会观察收到的邮件是否被你标记为垃圾邮件。在这种Email客户端中,你点击“垃圾邮件”按钮报告某些email为垃圾邮件,不会影响别的邮件。基于被标记为垃圾的邮件,您的电子邮件程序能更好地学习如何过滤垃圾邮件。请问,在这个设定中,任务 T 是什么?几秒钟后,该视频将暂停。当它暂停时,您可以使用鼠标,选择这四个单选按钮中的一个,让我知道这四个,你所认为正确的选项。它可能是性能度量值P。所以,以性能度量值P为标准,这个任务的性能,也就是这个任务T的系统性能,将在学习经验E后得到提高。
机器学习分类。
目前存在着几种不同的学习算法。主要的两种是:
- 监督学习(supervised learning)
- regression problem
- classification" problems
- 无监督学习
监督学习这个想法是指,我们将教计算机如何去完成任务,而在无监督学习中,我们打算让它自己进行学习。
其他还有:
强化学习和推荐系统等 各种术语。这些都是机器学习算法的一员,以后我们都将介绍到但学习算法最常用两个类型就是监督学习、无监督学习。
本课中,我们将花费最多的精力来讨论这两种学习算法
而另一个会花费大量时间的任务是
了解应用学习算法的实用建议。
我非常注重这部分内容,实际上,就这些内容而言
我不知道还有哪所大学会介绍到。给你讲授学习算法
就好像给你一套工具,相比于提供工具,可能更重要的
是教你如何使用这些工具。
我喜欢把这比喻成学习当木匠。想象一下,
某人教你如何成为一名木匠,说这是锤子,这是
螺丝刀,锯子,祝你好运,再见。这种教法不好,不是吗?
你拥有这些工具,但更重要的是,你要学会如何恰当地使用
这些工具。会用与不会用的人之间,存在着鸿沟。
尤其是知道如何使用这些机器学习算法的,与那些不知道
如何使用的人。在硅谷我住的地方,当我走访不同的公司,
即使是最顶尖的公司,很多时候我都看到
人们试图将机器学习算法应用于某些问题
有时他们甚至已经为此花了六个月之久。但当我看着
他们所忙碌的事情时,我想说,哎呀,我本来可以
在六个月前就告诉他们,他们应该采取一种学习算法
稍加修改进行使用,然后成功的机会绝对会高得多
所以在本课中,我们要花很多时间来探讨,
如果你真的试图开发机器学习系统,
探讨如何做出最好的实践类型决策,才能决定你的方式
来构建你的系统,这样做的话,当你运用学习算法时,就不太容易变成
那些为寻找一个解决方案花费6个月之久的人们的中一员。
他们可能已经有了大体的框架,只是没法正确的工作
于是这就浪费了六个月的时间。所以我会花
很多时间来教你这些机器学习、人工智能的最佳实践
以及如何让它们工作,我们该如何去做,硅谷和世界各地
最优秀的人是怎样做的。我希望能帮你成为最优秀的人才,
通过了解如何设计和构建机器学习和人工智能系统。
这就是机器学习,这些都是我希望讲授的主题。在下一个
视频里,我会定义什么是监督学习,
什么是无监督学习。此外,探讨何时使用二者。
机器学习是 AI 的一个分支
AI 的终极目标是制造出像人类一样智能的机器,尽管距离最终的目标还很遥远。许多AI 研究人员认为,实现这一愿景最好的方法就是通过学习算法模拟人类的大脑的学习方式。
本课程目标:
了解掌握机器学习前沿的原理
(但是仅仅掌握算法和原理,而不知道如何应用于实际的场景解决问题是不够了。)实际动手实现机器学习算法。
监督学习(supervised learning)
为了理解定义,先看一个例子:
假如你想预测房屋的价格。有一个数据集是这样的(房屋面积和其对应的价格)。在坐标系中显示如下:
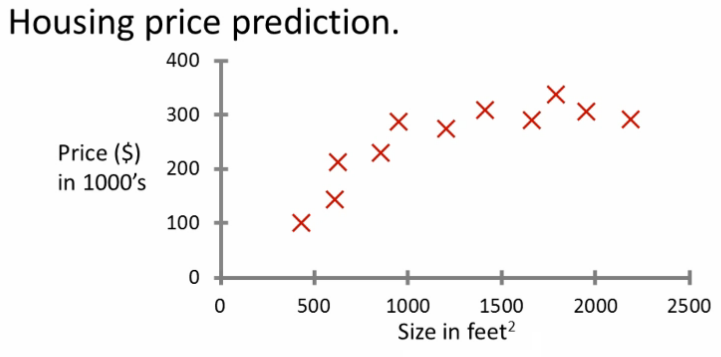
- 水平坐标代表房屋面积,单位是平方英尺;垂直方向代表房屋的价格,单位是1000美元。
如果你某个朋友拥有一套750平方英尺的房子,他想知道如果卖掉的话多少价钱合适。那么如何使用机器学习来预测这个房屋的价格呢?通过一些离散的采样数据,想要获得任何一点的相关数据的最好方法即使使用拟合函数。在这个图中,所有的数据都似乎接近于一条线上。如果使用一条直线进行拟合的话。类似下面的效果:

从上面的图中可以大致估计,750平方英尺大约能够卖150000美元(注意单位是1000美元/平方英尺)。
可以看到,直线的拟合效果并不好,途中的点会出现一整片区域位于线的同一侧的现象。整体看起来更像一条曲线。如果使用如下的曲线进行拟合。
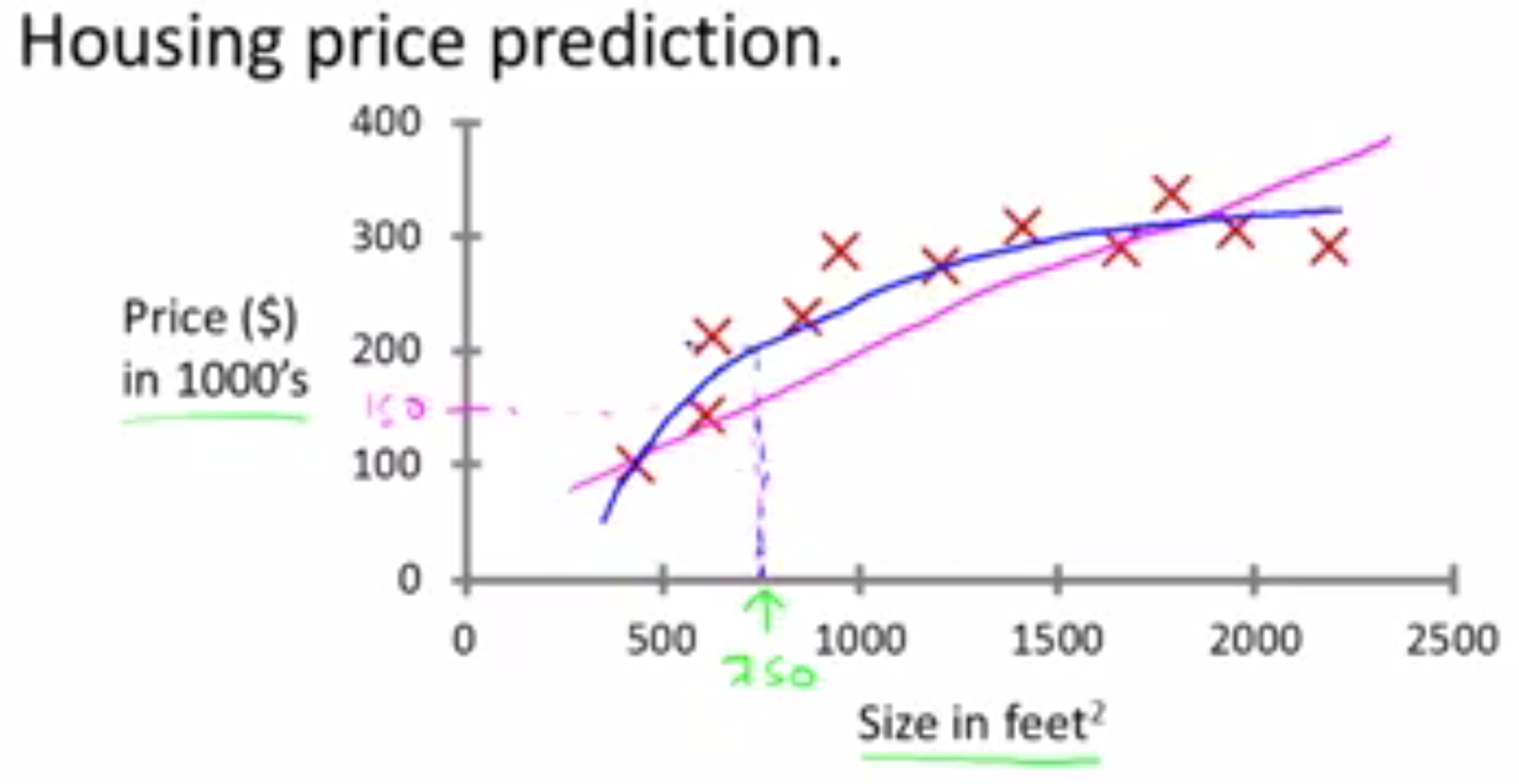
哇哦,这下能卖200000美元左右。稍后再来看如何选择一个拟合曲线来达到最好的效果。这里每一种都是一个学习算法。这个例子中展示的就是监督学习的算法。监督学习是指,对于一个算法,给出部分数据,并且都是正确的。在这个例子中,对于给定数据集中的每个数据,都知道对应的真实的卖出房价。由此,算法就能够计算出更多正确的价格。用一个更正式的术语称呼的话,就是“回归方程”,使用回归方程,我们能够预测出到任一个输入的价格输出。
另一个监督学习的例子
加入有一些乳腺肿瘤的病例。乳腺肿瘤分为良性和恶性,瘤块的大小和肿瘤是良性或者是恶性有着很大的相关性。假设这批数据中肿瘤大小和肿瘤是良性还是恶性呈现如下的关系。
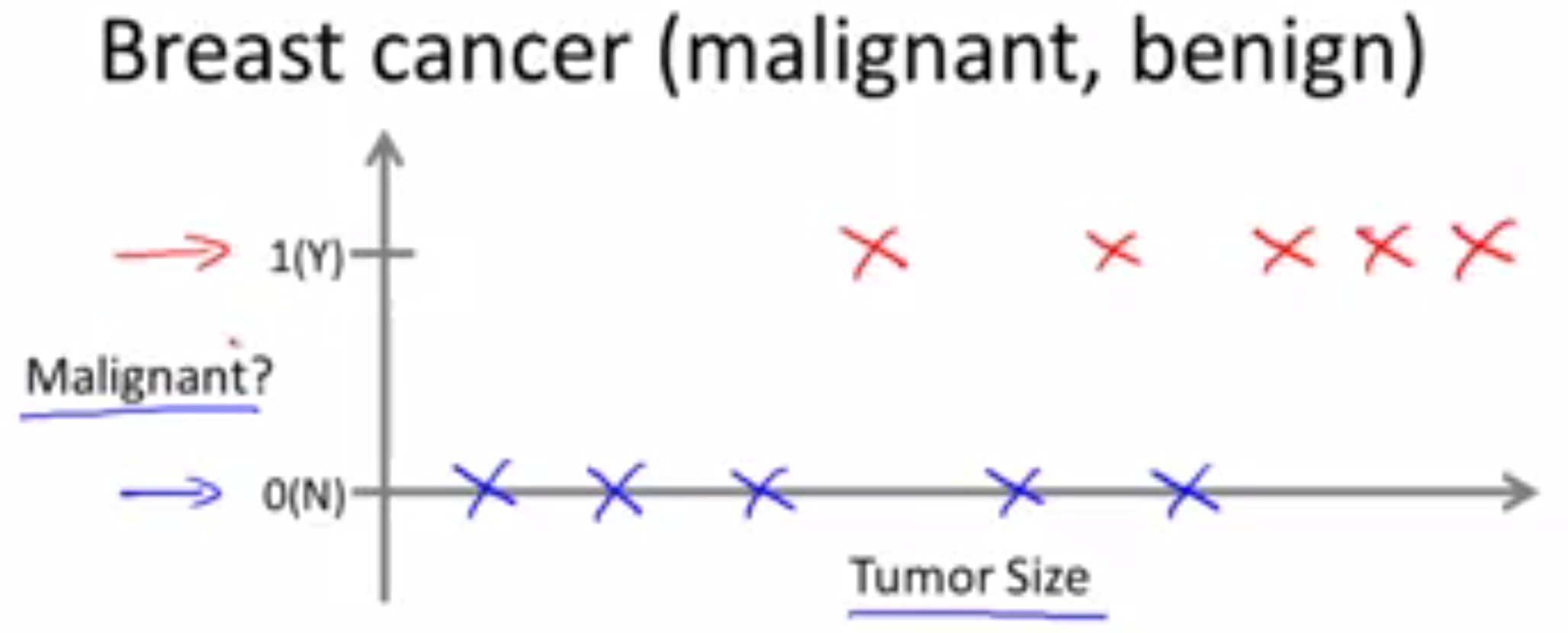
- 横轴表示肿瘤的大小,纵轴只有两个值:0代表良性,1代表恶性。
这个算法的目标是,根据一个输入,判断肿瘤是良性还是恶性的。这类问题的专业术语叫做分类问题。分类指的是,输出的结果是一些离散的,如0或1,良性或恶性。分类问题的结果并不一定只有两个,可以有更多离散的结果。
对于离散问题,结果可以使用不同的表示方法,在这个例子中。我们可以使用○和✘来表示不同的情况。将上面的表示进行转换: 0->○,1->✘。可以达到这样的表示。

更多的情况下,结果可能不止与一个属性相关。例如在乳腺癌病例中,肿瘤的良性和恶性还与年龄存在着某种关系。将年龄、肿瘤大小与肿瘤种类的关系绘制成如下的图表:
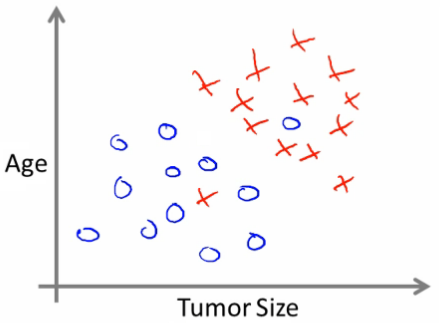
- 横坐标表示肿瘤大小,总坐标表示年龄。○表示良性肿瘤,✘表示恶性肿瘤。那么在这个数据集中,学习算法所做的就是画一条直线将两种结果分开。像这样:
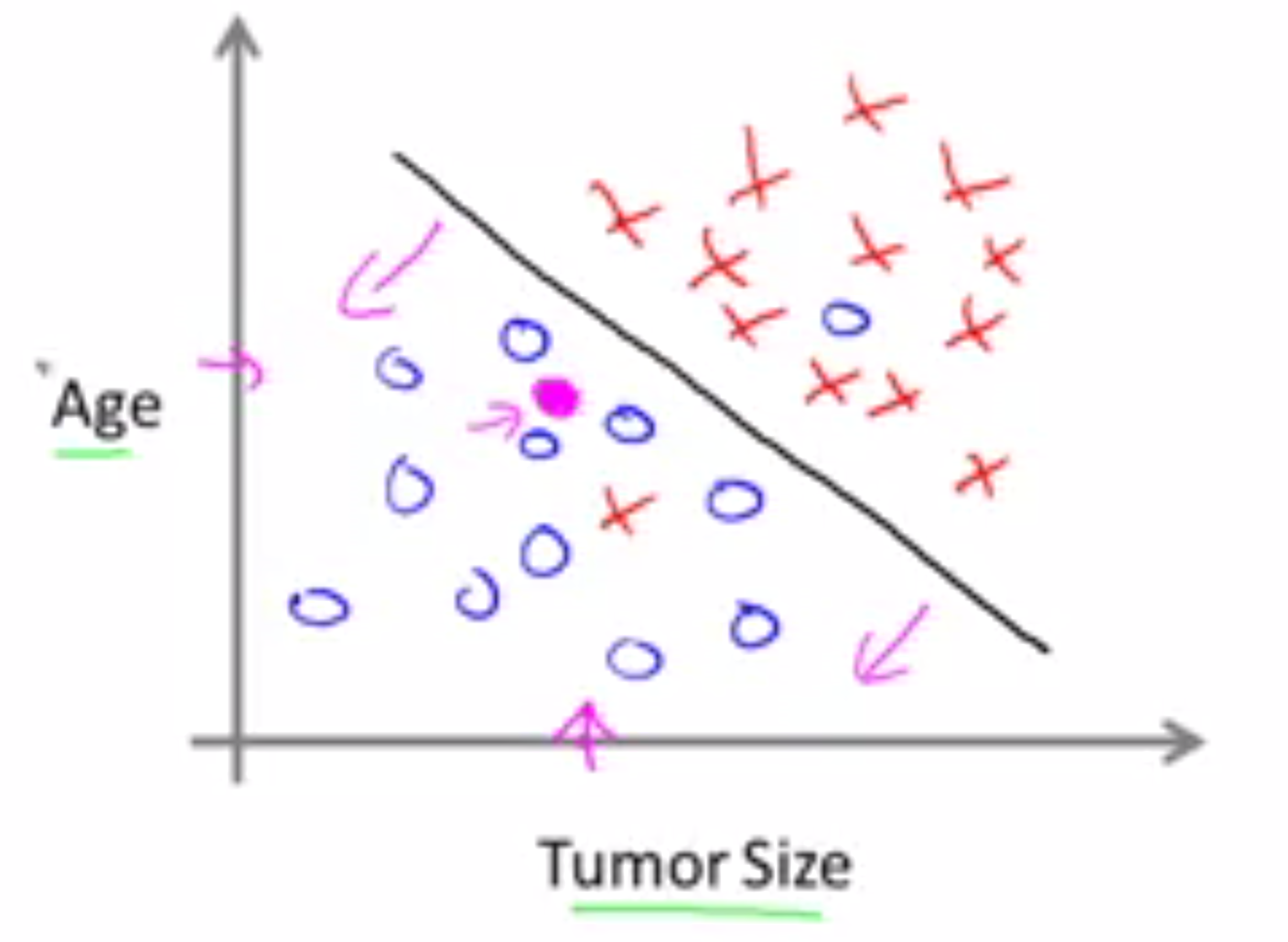
如果病人的年龄和这个肿瘤大小在线的左边,那结果预测是良性,如果在另一边,那是一个不幸的结果,恶性。这里共有两个特征:年龄、肿瘤大小。更又去的学习算法能过处理更多或者无穷多个特征。但对于一些学习问题,真要用到的不只是三五个特征,要用到无数多个特征,非常多的属性,所以,你的学习算法要使用很多的属性或特征、线索来进行预测。那么,你如何处理无限多特征呢?甚至你如何存储无数的东西进电脑里,又要避免内存不足?事实上,等我们介绍一种叫支持向量机的算法时,就知道存在一个简洁的数学方法,能让电脑处理无限多的特征。 监督学习的基本思想是,对于数据集中的每个数据,都有相应的正确答案,(训练集)算法就是基于这些来做出预测。就像那个房价,或肿瘤的性质。
下面是个小测验题目: 假设你有家公司,希望研究相应的学习算法去解决两个问题。第一个问题,你有一堆货物的清单。假设一些货物有几千件可卖,你想预测出,你能在未来三个月卖出多少货物。第二个问题,你有很多用户,你打算写程序来检查每个用户的帐目。对每个用户的帐目,判断这个帐目是否被黑过(hacked or compromised)。请问,这两个问题是分类问题,还是回归问题?
问题一是个回归问题因为如果我有几千件货物,可能只好把它当作一个实际的值,一个连续的值。也把卖出的数量当作连续值。第二个问题,则是分类问题,因为可以把我想预测的一个值设为0,来表示账目没有被hacked。另一个设为1,表示已经被hacked。就像乳癌例子中,0表示良性,1表示恶性。所以这个值为0或1,取决于是否被hacked,有算法能预测出是这两个离散值中的哪个。因为只有少量的离散值,所以这个就是个分类问题。