本课要点
- linear regression
- 监督学习的整个过程是什么样子的。
这有一个预测房屋价格的例子,其中房屋价格的数据集是这样的:
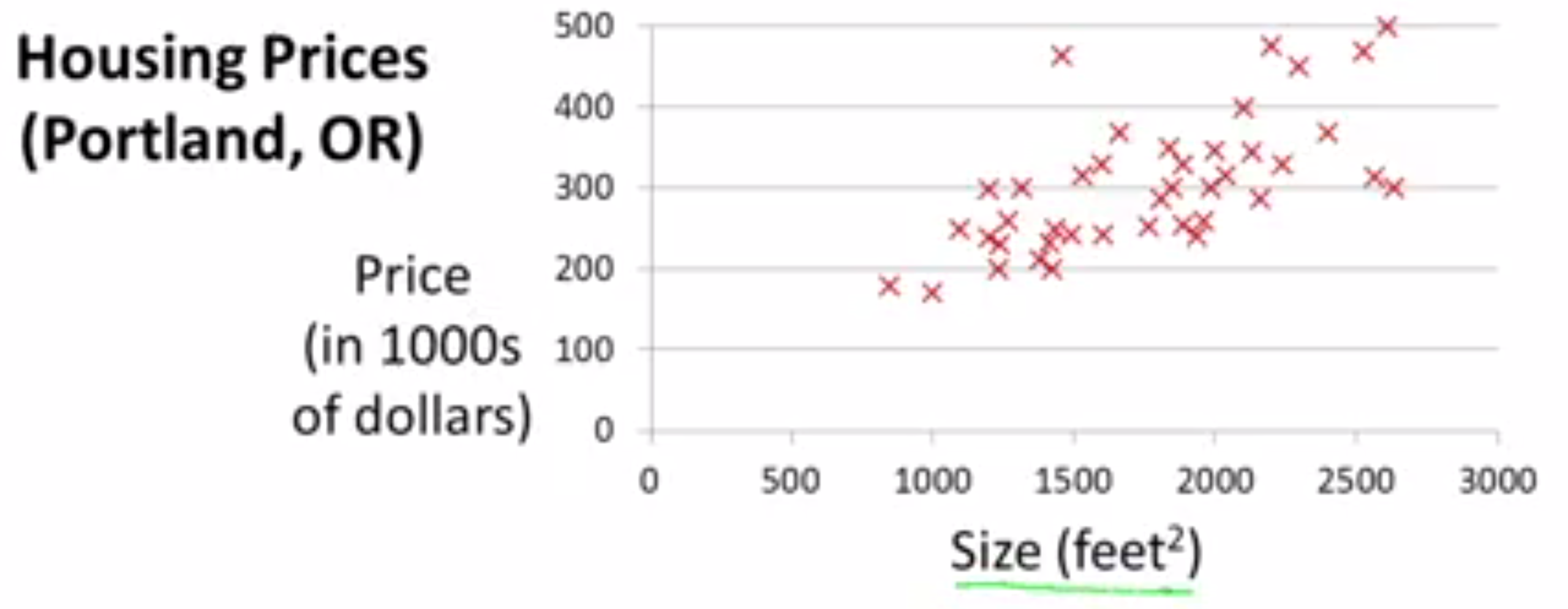
有一套1250feet2 的房子,想要知道这套房子能卖多少钱。根据已有的数据需要构建一个模型,如果是直线型,根据这个数据集构建的模型大致是这样的:
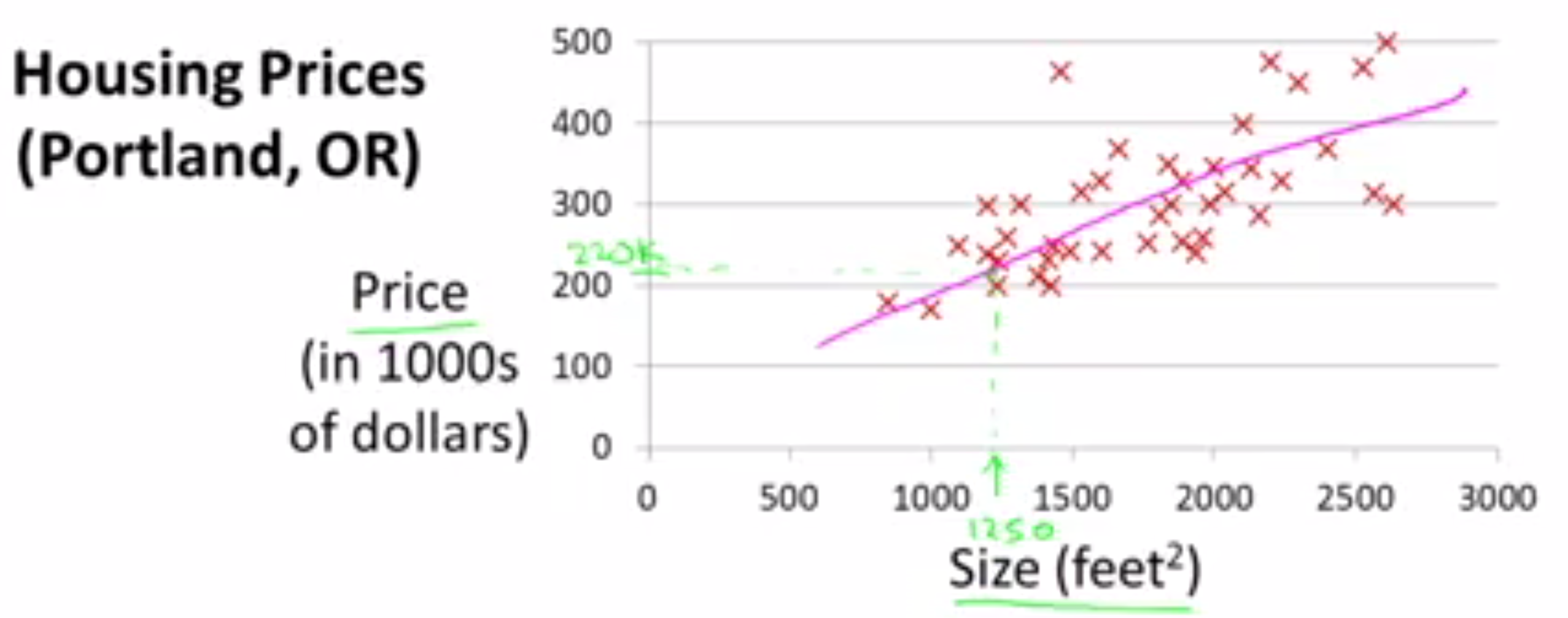 从直线模型中可以得到大致220000美元。
从直线模型中可以得到大致220000美元。
这个例子被归类为监督学习,因为对于每个数据,都给出了“正确答案”,即:对于确定的房屋面积,房屋的价格是多少。更确切的说,是监督学习中的线性回归问题,回归是指:根据已有的数据,预测任意给定输入的输出值。对于这个立即就是房屋价格。
训练集
在监督学习中已有的数据集被称为训练集。对于预测房屋价格的例子,训练集就是已知的房屋面积和价格。
课程中使用到的符号
m : 训练集的数量,对于上面的例子。如果已知的房屋价格有47个,则m=47. x : 输入值、也称作特征量 y : 输出变量,也称作目标量 (x, y) : 表示一个训练样本。为了指出某个训练样本,可以使用(x(i), y(i))表示第i个训练样本。
测试题

以上就是学习算减的工作流程,它大致是这样的:给学习算法(Learning Algorithm)喂一个数据集(Training Set),它将输出一个函数h,(h表示hypothesis(假设),之所以这样叫是因为早期的机器学习资料中这样叫,现在成了机器学习的标准用语)。函数h是关于输入和输出的函数。对于上面的例子,输入为房屋的面积x,输出为房屋的价格y。h是x到y的一个函数映射。
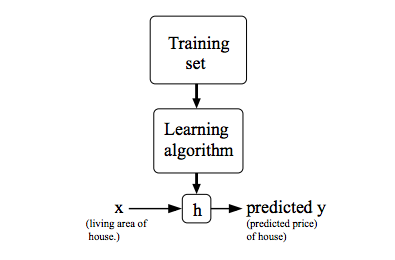 机器学习算法的重点是,如何得到这个函数h,对于一个未知的线性函数,通常这样表示:
机器学习算法的重点是,如何得到这个函数h,对于一个未知的线性函数,通常这样表示:
hθ(x) = θ0 + θ1x
该函数就是线性回归模型(Linear Regression),并且是线性回归中的单变量线性回归,这个变量就是x。其中 θi被称为模型参数。
在单变量线性回归中如何计算θ0和θ1
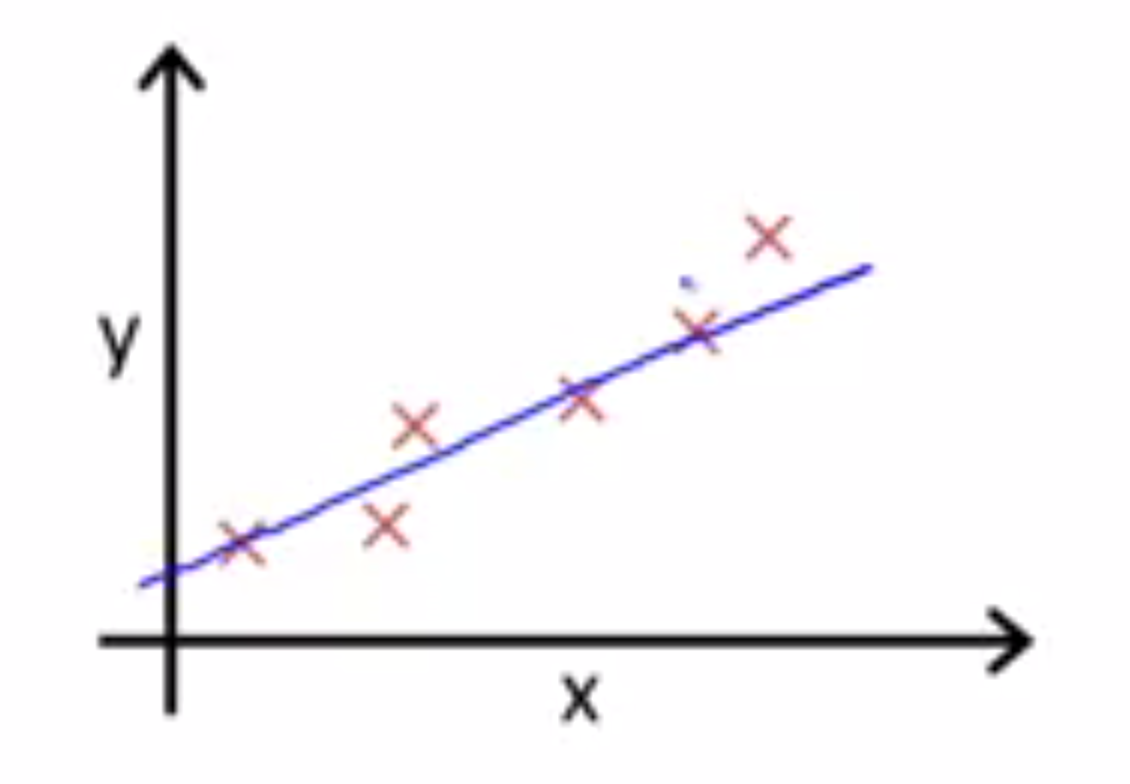
计算点变量线性回归的思路是,要想让这些点尽量和结果的线靠近,一个好的方法是计算点到直线的距离最小。这将求θ0,θ1转换成了一个最小化问题。
要使距离最小 就要求|hθ(x) - y| 最小,对于绝对值不好求,可以使用其平方 (hθ(x) - y)2
对于所有的已知数据集,我们希望算出所有的距离平均最小。因此就是求:
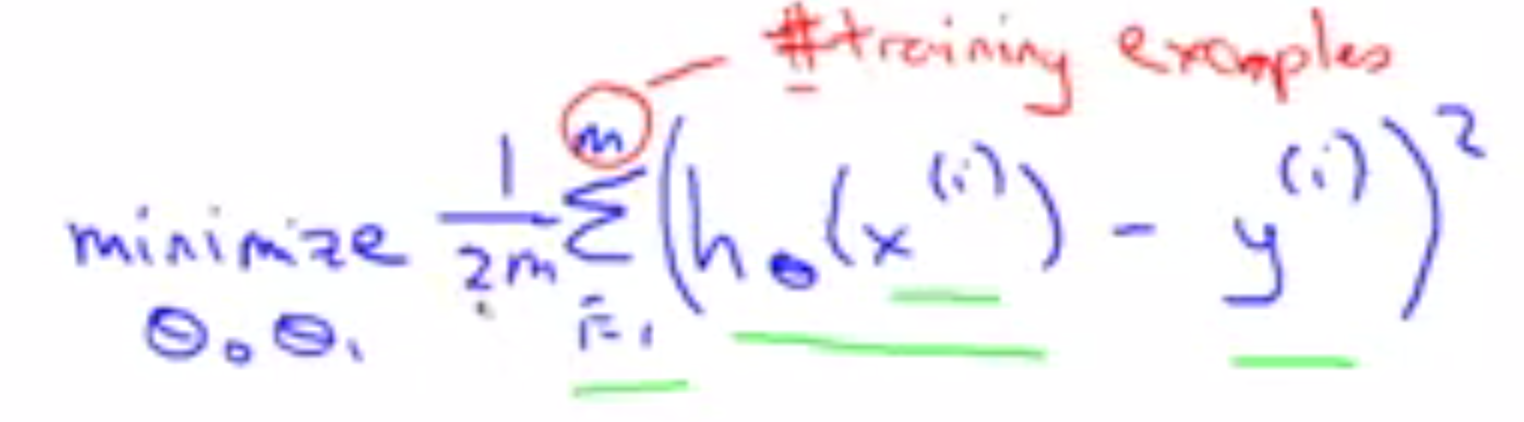
其中m就是数据集的数量。hθ(x(i)) = θ0 + θ1x(i)
要求θ0,θ1就变成了一个关于θ0,θ1的函数。对上面的函数进行改写:
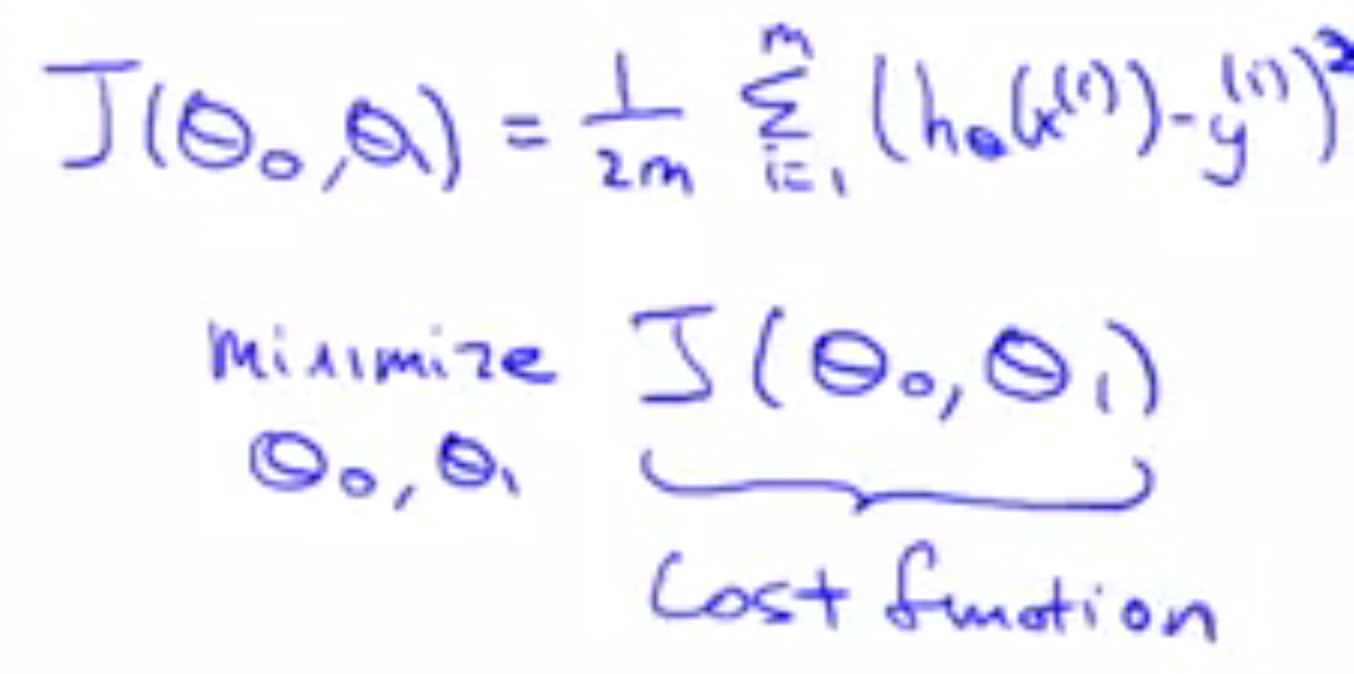
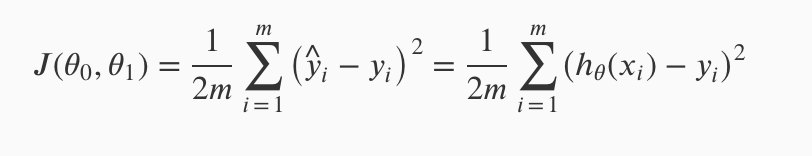
To break it apart, it is 12 x¯ where x¯ is the mean of the squares of hθ(xi)−yi , or the difference between the predicted value and the actual value.
上面的式子也叫平方误差方程。
平方误差方程的样子 以下是为了对平方误差方程有一个直观的感受做的一个特化。
首先简单一点,将θ0假设为0,这时候hθ(x) = θ1x。是一条经过原点的直线。此时平方误差函数变成一条关于θ1的函数:
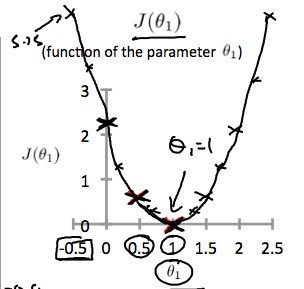
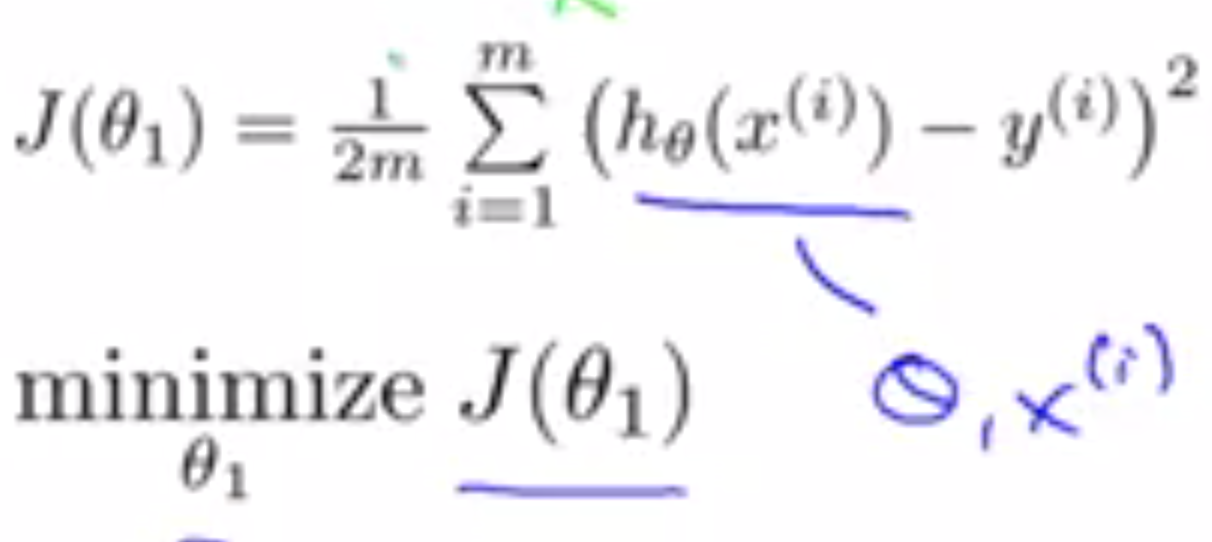 hθ(x)是一条关于x的函数,而J(θ1)是关于θ1的函数。假设有这样一个数据集,(1,1),(2,2),(3,3)。θ1取不同值时,hθ(x)将取得不同的拟合效果,此时J(θ1)也将对应的取得不同的值。θ1,取-0.5,0,0.5,1,1.5,2,2.5时,J(θ1)将得到如下的点。将它们用一条曲线连接起来,可以得到一条开口向上的抛物线。
hθ(x)是一条关于x的函数,而J(θ1)是关于θ1的函数。假设有这样一个数据集,(1,1),(2,2),(3,3)。θ1取不同值时,hθ(x)将取得不同的拟合效果,此时J(θ1)也将对应的取得不同的值。θ1,取-0.5,0,0.5,1,1.5,2,2.5时,J(θ1)将得到如下的点。将它们用一条曲线连接起来,可以得到一条开口向上的抛物线。
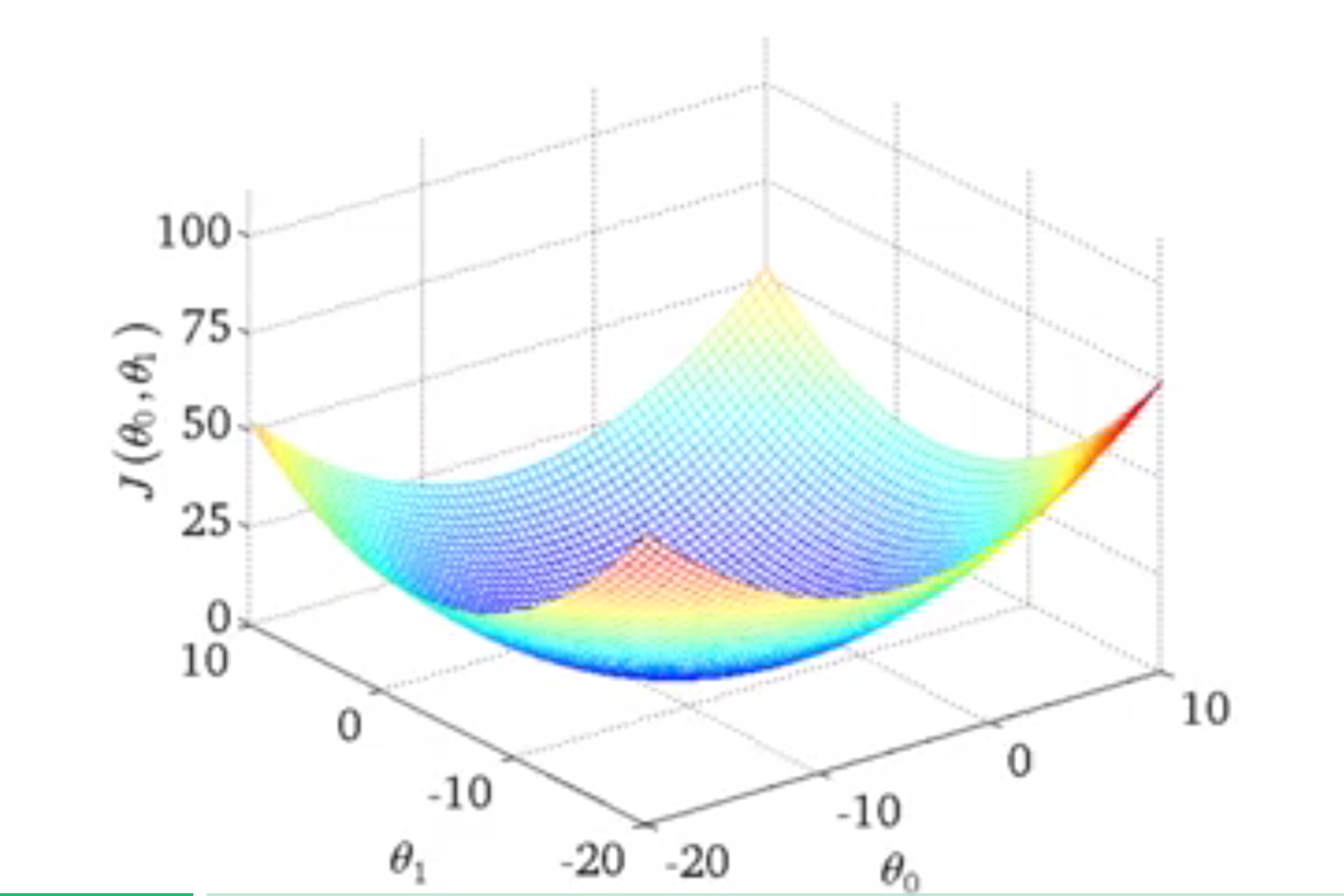
看了单个变量的平方误差函数之后,来看一下θ0和θ1,两个变量时平方误差函数的样子。
在变量时一个的时候,取得的是一个抛物线,而对于两个变量,它将变成一个三维的抛物面。类似
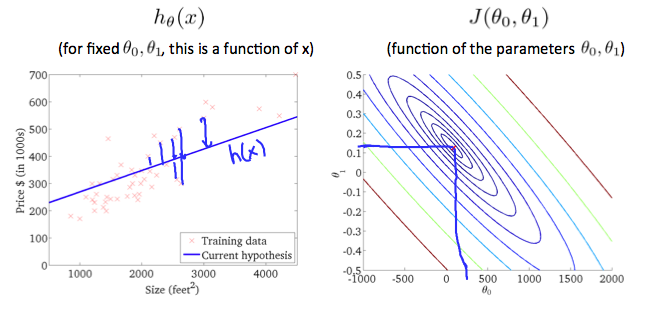
 随着θ0和θ1的改变,J(θ1,θ0)将得到曲面上不同点的值。三维曲面还有另一种表示方法,那就是轮廓图(contour plot或contour figure意思一样)。想象着用一个平行于θ0和θ1面的平面去截这个曲面,得到的是一个个圆环,圆环上所有J(θ1,θ0)点的值都是相同的。
随着θ0和θ1的改变,J(θ1,θ0)将得到曲面上不同点的值。三维曲面还有另一种表示方法,那就是轮廓图(contour plot或contour figure意思一样)。想象着用一个平行于θ0和θ1面的平面去截这个曲面,得到的是一个个圆环,圆环上所有J(θ1,θ0)点的值都是相同的。
Parameter Learning
在学习了平方误差函数之后,为了取得函数的最小值,将用到梯度下降算法(gradient descent),用于取得平方误差函数的最小值。梯度下降是很常用的算法,它不仅用在线性回归上,实际上它被用在机器学习的诸多领域中。在后面课程中,为了解决其他线性问题,也将用梯度下降法最小化其他函数。这里将使用梯度下降算法来最小化平方误差函数。 问题概述:对于函数J(θ0, θ1),也许是线性回归函数,也许是其他类型函数。要使其最小化,需要使用一个算法。梯度下降算法可以应用于多种多样的问题求解,例如对于函数J(θ0,θ1,θ2 ...θn)希望最小化该函数,而梯度下降算法就可以应用于这种更多维度的情况。为了简介,以下使用示例只使用了两个参数。
梯度下降算法的核心思想: 对于函数J(θ0, θ1), 要求得:$$\\begin{gather} \min_{\theta0, \theta1}J(\theta0, \theta1) \end{gather}\$$
Outline:
- Start with some $$\\theta_0, \theta_1\$$
- Keep changing $$\\theta_0, \theta_1\$$ to reduce $$\J(\theta_0, \theta_1)\$$ until we hopefully end up at a minumum。
首先要做的,就是对$$\\theta_0, \theta_1\$$进行一些初步的猜测,它们到底是什么其实并不重要,但通常将$$\\theta_0 \$$设为0,将$$\\theta_1\$$也设为0。然后就是不停的改变$$\\theta_0\$$和$$\\theta_1\$$,试图通过这种改变使得$$\J(\theta_0, \theta_1)变小\$$,直到找到J的最小值,或许是局部最小值。下面的图片演示了梯度下降的工作过程。
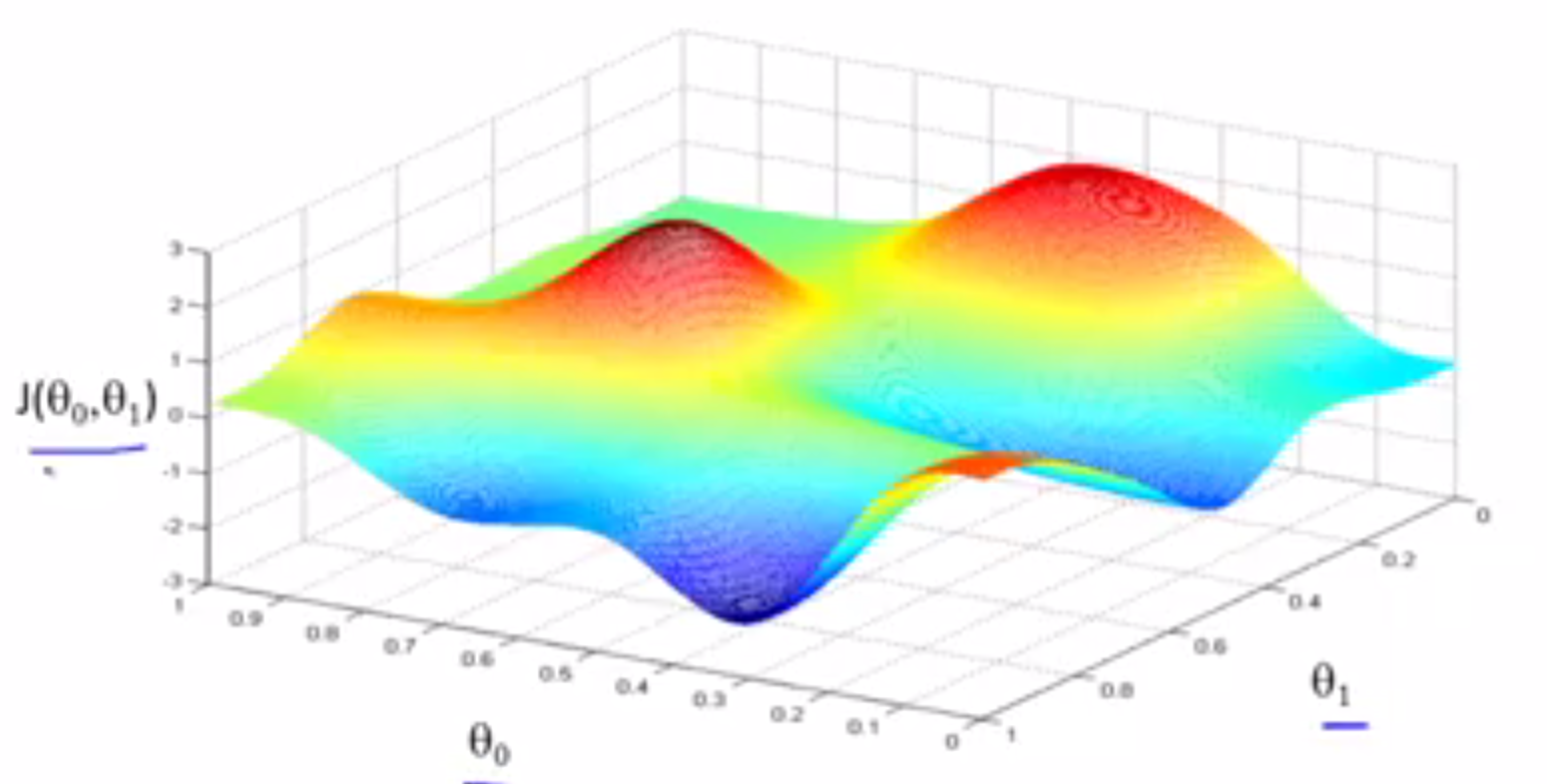 水平轴为$$\\theta_0\$$和$$\\theta_1\$$,函数J在垂直坐标轴上,图形表面高度则为J的值,想要求得函数J的最小值(局部最小值),需要$$\\theta_0\$$和$$\\theta_1\$$从某个值出发,所以想象一下对$$\\theta_0\$$和$$\\theta_1\$$赋予某个初值,也就是对应函数J曲面上的某一点出发
水平轴为$$\\theta_0\$$和$$\\theta_1\$$,函数J在垂直坐标轴上,图形表面高度则为J的值,想要求得函数J的最小值(局部最小值),需要$$\\theta_0\$$和$$\\theta_1\$$从某个值出发,所以想象一下对$$\\theta_0\$$和$$\\theta_1\$$赋予某个初值,也就是对应函数J曲面上的某一点出发
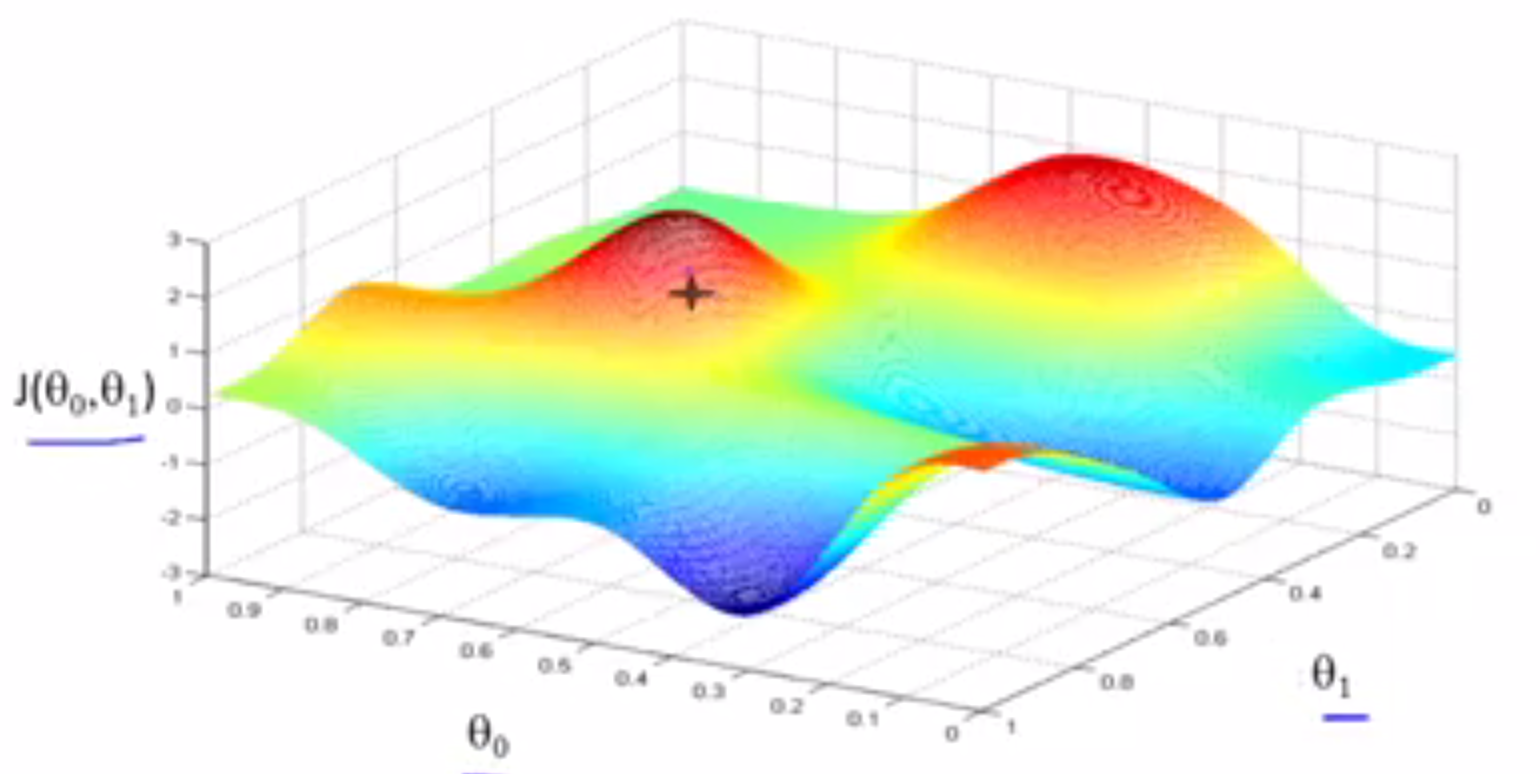 所以$$\\theta_0\$$和$$\\theta_1\$$初始值的寻去是多少无所谓,在这个图像中,可以将凸起的部分想象成山峰,此时你正在上的这一点上,在梯度下降算法中,我们要做的就是环顾四周,并问自己,我想在改点上用小步尽快下山,我需要将小碎步迈向什么方向?当然是最陡峭的方向,大约在这个方向
所以$$\\theta_0\$$和$$\\theta_1\$$初始值的寻去是多少无所谓,在这个图像中,可以将凸起的部分想象成山峰,此时你正在上的这一点上,在梯度下降算法中,我们要做的就是环顾四周,并问自己,我想在改点上用小步尽快下山,我需要将小碎步迈向什么方向?当然是最陡峭的方向,大约在这个方向
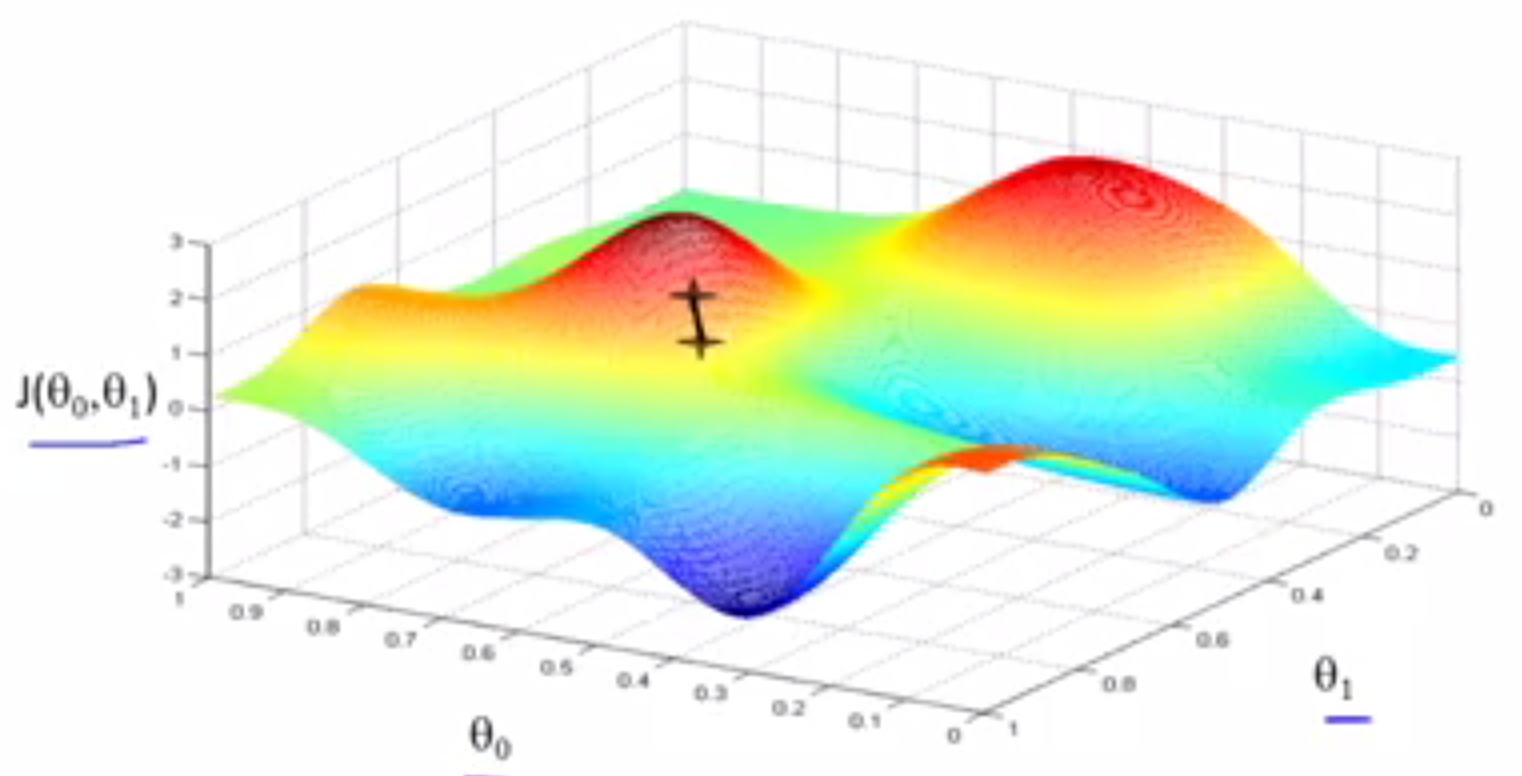 迈出一步后,现在你在山上新的起点上,需要做的就是再次环顾四周,然后思考,我应该朝哪个方向走才能尽快下上,如此重复。一步一步走,知道到达局部最低点的位置。
迈出一步后,现在你在山上新的起点上,需要做的就是再次环顾四周,然后思考,我应该朝哪个方向走才能尽快下上,如此重复。一步一步走,知道到达局部最低点的位置。
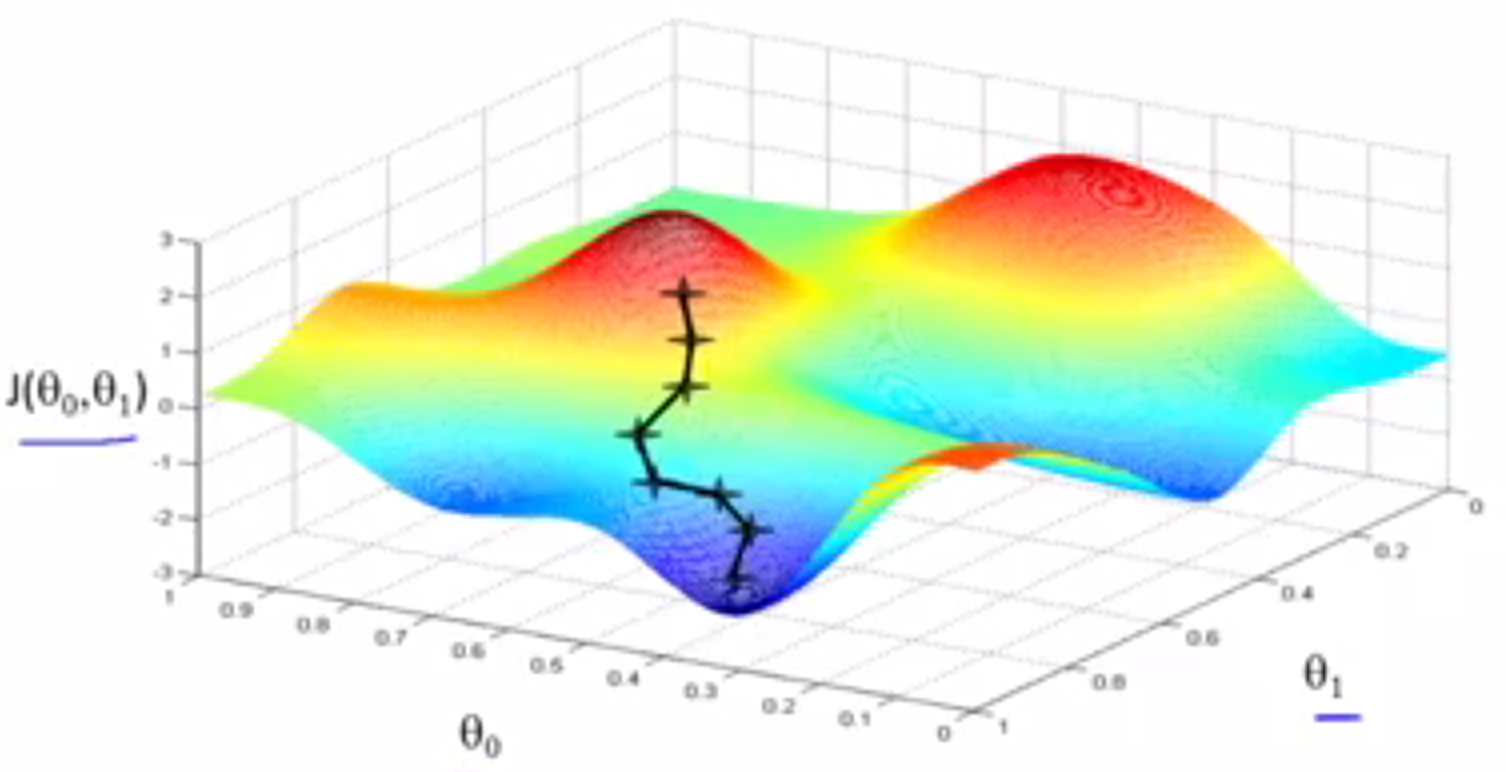
这种下降有一个有趣的特点,对于不同的起始值,可能得到不同的局部最小值。例如从另一个位置出发,开始使用梯度下降算法。将会得到不同的局部最优值。
起始点不同,可能会得到一个不同的局部最优解。
Gradient descent algorithm
repeat until convergence {
$$\\begin{gather} \theta_j := \theta_j - \alpha\frac{\partial}{\partial\theta_j} J(\theta0, \theta1) \qquad (for\quad j = 0\quad and\quad j = 1) \end{gather}\$$ }
重复上面的步骤,跟新$$\\theta_j\$$直到收敛,
注意点:
- := 表示赋值,与a = b 不同。
- α 是一个数字,被称为学习速率(learning rate)。在梯度下降算法中,它控制了我们下山时,迈出多大的步子,如果α很大,相应地在梯度下降过程中,我们试图使用大步下山,如果α很小,那么我们会迈着很小的碎步下山。
- 在梯度下降过程中,需要同时更新$$\\theta_0, \theta_1\$$。这意味着在计算中需要这样计算:
$$\\begin{gather} temp0 := \theta_0 - \alpha\frac{\partial}{\partial\theta_0} J(\theta0, \theta1) \
temp1 := \theta_1 - \alpha\frac{\partial}{\partial\theta_1} J(\theta0, \theta1)\
\theta_0 := temp0 \
\theta_1 := temp1
\end{gather}\$$
而不是
$$\\begin{gather} temp0 := \theta_0 - \alpha\frac{\partial}{\partial\theta_0} J(\theta0, \theta1) \
\theta_0 := temp0 \
temp1 := \theta_1 - \alpha\frac{\partial}{\partial\theta_1} J(\theta0, \theta1)\
\theta_1 := temp1
\end{gather}\$$ 这种错误是$$\\theta_0, \theta_1\$$没有同步更新,先更新了$$\\theta_0$$,然后将更新后的$$\\theta_0$$用于更新$$\\theta_1$$。这种计算并不具有梯度下降的性质。
梯度下降算法更新过程的意义
目标:
- 对α和偏导数部分有一个更直观的认知,这两部分有什么用,以及为什么把这两部分放到一起时,整个过程是有意义的。
为了更好的理解整个过程,以及在演示过程中,方便计算。需要对梯度下降算法做一个简化,令$$\\theta0 = 0\$$,这时$$\\begin{gather}\min{\theta0, \theta_1}J(\theta_0, \theta_1) \end{gather}\$$就会简化成$$\\begin{gather}\min{\theta_1}J(\theta_1) \end{gather}\$$。$$\\theta_1\$$是一个实数,这样的话,可以画一条曲线表示函数J,假如它是这样:
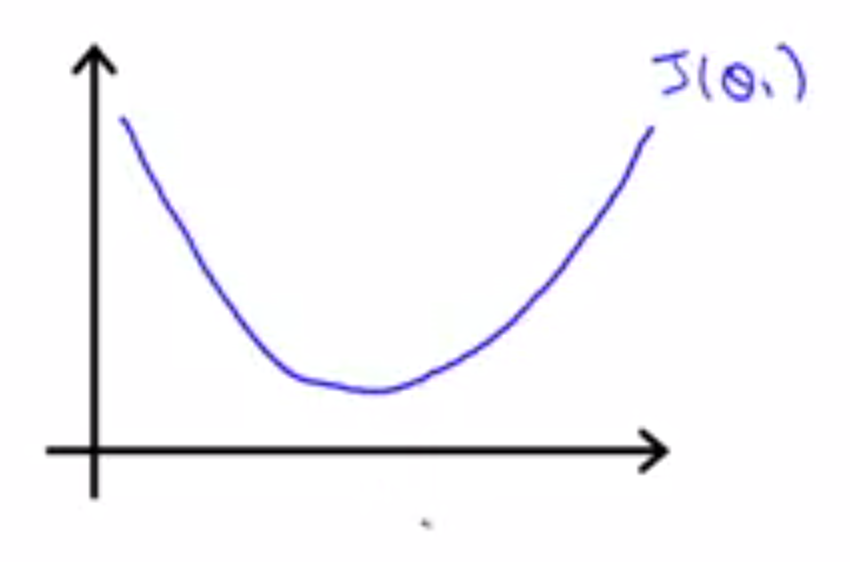 梯度算法第一步就是随便选一个点对$$\\theta_1\$$初始化,然后从这个点出发,进行梯度下降。
要做的事情就是不断的更新$$\\theta_1\$$等于$$\\theta_1\$$减去$$\\alpha\$$倍的$$\\frac{d}{d\theta_1}J(\theta_1)\$$
梯度算法第一步就是随便选一个点对$$\\theta_1\$$初始化,然后从这个点出发,进行梯度下降。
要做的事情就是不断的更新$$\\theta_1\$$等于$$\\theta_1\$$减去$$\\alpha\$$倍的$$\\frac{d}{d\theta_1}J(\theta_1)\$$